Nova计算服务组件是OpenStack中非常重要、核心的部分,负责承载和管理云计算系统,与其他组件有密切关系。
Nova计算服务组件使用基于消息,无共享、松耦合无状态的架构。OpenStack项目中的核心服务组件都运行在多台主机节点上,包括Nova,cinder,neutron,swift和glance等服务组件,状态信息都存储在数据库中。控制节点服务通过HTTP与内部服务进行交互,但与scheduler服务、网络和卷服务的通信依赖高级消息队列协议进行。为避免消息阻塞而造成长时间等待响应,Nova计算服务组件采用异步调用的机制,当请求被接收后,响应被触发,发送回执,而不关注该请求是否被处理。
OpenStack项目中的控制节点服务影响着整个云环境的状态,API服务器为控制节点作为web服务前端而服务,处理各种交互信息,计算节点提供各种计算资源和计算服务,Nova计算服务组件中的网络服务提供虚拟网络。
- driver框架
OpenStack作为开放的云操作系统,其开放性体现在采用了基于driver的框架。以nova为例,OpenStack的计算节点支持多种hypervisor。包括KVM、hyper-V、VMware、XEN、docker等。
Nova-compute为这些hypervisor定义了统一的接口,hypervisor只需要实现这些接口就可以driver的形式插入到OpenStack中去使用。
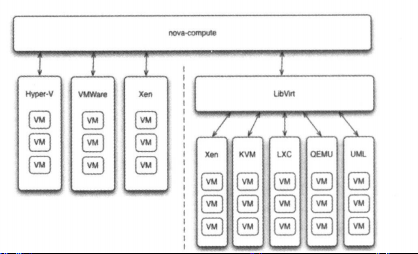
在nova-compute的配置文件/etc/nova/nova.conf中,由compute-driver配置项指定该计算节点使用哪一种hypervisor的driver。

- 关于messaging
在创建虚拟机的过程中,nova-*子服务之间的调用严重依赖messaging。这是因为它是采用了异步调用的方式。
- 同步调用
API直接调用scheduler的接口就是直接调用,其特点是API发出请求后需要一直等待,直到scheduler完成对compute的调度,将结果返回给API后API才能够继续做后面的工作。
- 异步调用
API通过messaging间接调用scheduler就是异步调用,其特点就是API发出请求后不需要等待,直接返回,继续做后面的事。scheduler从messaging接收到请求后执行调度,完成后将结果也通过messaging发送给API。
好处:
- 解耦各子服务:子服务不需要知道其他服务运行在哪里,只需要发送消息给messaging就能完成调度
- 提高性能:无需等待返回结果,这样就可以执行更多的工作,提高系统的吞吐量。
- 提高伸缩性:子服务可以根据需要进行扩展,启动更多的实例处理更多的请求,在提高可用性的同时也提高了整个伸缩性。而且这种变化不会影响到其他子服务。
nova组件
- Nova-api service:负责对终端用户调用compute API的接收和反馈
- Nova-api-metadata:负责接收虚拟机对metadata(元数据)访问请求,一般部署nova-network的多主机模式才会用nova-api-metadata。
- Nova-compute:该服务通过hypervisor APIs(XenAPI、libvirt for KVM or QEMU、VMwareAPI)创建和终止虚拟机实例。该服务接收消息队列中的信息,执行一系列操作命令,如创建和更新虚拟机实例状态。
- Nova-scheduler:该服务接收消息队列中的请求,从而决定虚拟机实例运行在哪个计算节点上。
- Nova-conductor:nova-compute经常需要更新数据库,但是出于安全性和伸缩性的考虑,nova-compute不会直接访问数据库,而是交由nova-conductor去处理,并且这两个服务不能安装在同一个节点上。
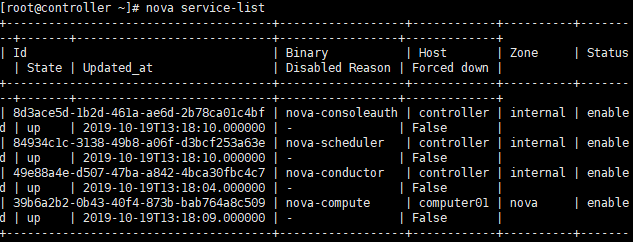
我们可以通过nova service-list查看具体安装了哪些组件:
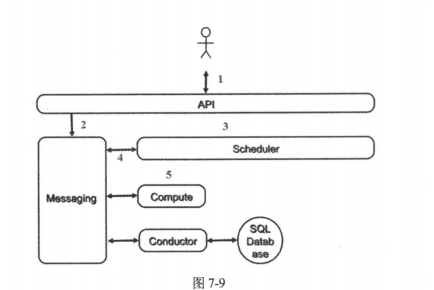
请求流程
- 客户或程序向api(nova-api)发送创建虚拟机的请求。
- API对请求做一些必要的处理后,向message(rabbitMQ)发送了消息,让scheduler创建一个虚拟机
- scheduler从messaging获取到API发送的请求后,执行调度算法,从若干节点中选出节点A。
- scheduler向messaging发送消息,告知在A上创建这个虚拟机
- 计算节点A的compute(nova-compute)从messaging中获取到scheduler发给他的消息后,然后在本节点的hypervisor上启动虚拟机。
而对于其中nova-compute而言,它所做的事有这些:
(1)为instance准备资源,根据指定的flavor依次为instance分配内存、磁盘和vCPU。
(2)创建instance的镜像文件,它会先检查是否已经下载,如果没有,则会先向glance去下载相应的镜像文件到本地,然后通过qemu-img创建镜像。
(3)创建实例的XML文件
(4)创建虚拟网络以及启动实例
在虚机创建的过程中,compute如果需要查询或者更新数据库信息,会通过messaging向conductor(nova-conductor)发送消息。
调度方式
在nova.conf中,nova通过schedulerdriver、scheduleravailable_filters和schedulerdefaultfilters这三个参数来配置nova-scheduler。
1、filter scheduler
它是nova-scheduler默认的调度器,调度过程分为两步:
- 通过过滤器(filter)选择满足条件的计算节点
- 通过权重计算选择在最优(权重值最大)的计算节点上创建instance。

它也允许使用第三方scheduler,配置好driver就行。也可以使用多个filter一次进行过滤,过滤之后的节点再通过计算权重选出最合适的节点。
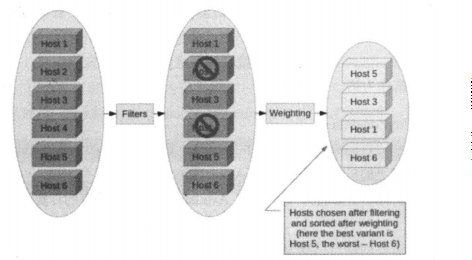
- 开始有6个计算节点
- 通过filter过滤,刷了两个
- 然后计算权重,权重高的host5入选
2、filter
当filterscheduler需要执行调度操作的时候,会让filter对计算节点进行判断,返回true或者false。
Nova.conf中available_filters选项用于配置配置可用的filter:

另外还有一个选项用于指定scheduler真正使用的filter,默认值:

Filter scheduler将按照列表中的顺序依次过滤。
- Retryfilter
作用是刷掉之前已经调度过的节点。比如说A、B、C三个节点都通过了过滤,最终A因为权重最大被选中,但是由于某个原因,操作在A上失败了,默认情况下nova-scheduler会重新执行过滤操作(默认是3,max_attempts),那么这时候retryfilter就会将A直接刷掉,避免操作再次失败。
- Availabilityzonefilter
为提高容灾性和提供隔离服务,可以将计算节点划分到不同的availability zone中。OpenStack默认有一个命名为nova的availability zone,所有的计算节点初始都放在nova中。创建instance时,需要指定将instance部署到在哪个zone中。在做filter的时候,将不属于指定zone的计算节点过滤掉。
- Ramfilter
将不能满足flavor内存需求的计算节点过滤掉。需要注意的是:为了提高系统的资源使用率,OpenStack在计算节点可用内存是允许overcommit,也就是说可以超过实际内存的大小。超过的程度通过文件中参数来控制:

- Diskfilter
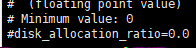
将不能满足flavor磁盘需求的计算节点过滤掉,和上面一样,允许overcommit。
- Corefilter
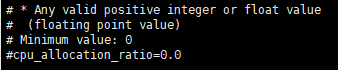
将不满足flavor vcpu需求的计算节点过滤掉。
- Computefilter
保证只有nova-compute服务正常工作的计算节点,才能够被调度。
- Computecapabiliesfilter
如果想将instance指定部署到x86_64架构的节点上,就可以利用它。
- Imagepropertiesfilter
根据所选image的属性来筛选匹配的计算节点。跟flavor类似,image也有metadata用于指定其属性
- Servergroupantiaffinityfilter
可以尽量将instance分散部署到不同的节点上。为保证分散部署,可以进行如下操作:
1 | • 创建一个anti-affinity策略的server group: |
- Servergroupaffinityfilter
与上面一个相反,它会尽量将instance部署到同一个计算节点上。
1 | Nova server-group-create --policy affinity group-1 |
3、weight
经过过滤,scheduler选出能够部署instance的计算节点,nova-scheduler会通过计算节点空闲的内存量计算权重值:空闲内存越多,权重越大。

